Overview
The lisp-rs project implements an interpreter, in Rust, for a small subset of Scheme, a Lisp dialect. The main goal of this document is to make sure the reader understands the inner details of how the interpreter was implemented.
The project was inspired by Peter Norvig's article (How to Write a (Lisp) Interpreter (in Python)) and the book Writing An Interpreter In Go. This document serves as a commentary on the code that implements the interpreter. Rust's rich programming constructs such as enum, pattern matching, and error handling make it easy and a joy to implement this bare-bone interpreter.
Pre-requistes
To make the most out of this project, it is expected that the user is aware of the following Computer Science concepts
Rust is a non-trivial language, however, to implement the Lisp interpreter, the reader needs to have moderate experience with the language. Knowing the following four concepts should be enough for the user to understand the whole project
Lisp Dialect
In order to keep the interpreter simple and its implementation easy to understand, the number of features supported by it has been limited on purpose. Following are the data types and statements that will be supported by the interpreter.
Data types
- integer
- boolean
Statements
- variable definition and assignment
- if-else
- function definition using lambdas
- function calls
Keywords
- define
- if-else
- lambda
Examples
Following are some of the sample programs that you will be able run using the interpreter
(
(define factorial (lambda (n) (if (< n 1) 1 (* n (factorial (- n 1))))))
(factorial 5)
)
(
(define pix 314)
(define r 10)
(define sqr (lambda (r) (* r r)))
(define area (lambda (r) (* pix (sqr r))))
(area r)
)
Interpreter
The interpreter will be implemented from scratch and without the help of any tools such as nom or pest. The interpreter implementation is broken down into four parts
- Lexer ~ 20 lines of code
- Parser ~ 60 lines of code
- Evaluator ~ 170 lines of code
- REPL ~ 30 lines of code
The best way to understand the implementation of the interpreter is to check out the code and walk through it while reading this document.
git clone https://github.com/vishpat/lisp-rs
git checkout 0.0.1
Once you thoroughly understand the implementation, you will be equipped to add new features to it, such as support for new data types like strings, floating-point numbers, lists, or functional programming constructs such as map, filter, reduce functions, etc.
REPL
To run the interpreter and get its REPL (Read-Eval-Print-Loop)
cargo run
Introduction
Lisp is an abbreviation for List Processor. Every Lisp program is simply a list. The elements of this list can either be atomic values such as an integer or a string or another list. Thus a Lisp program is a recursive list as shown below.
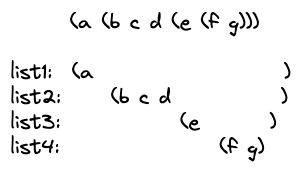
The Lisp interpreter is a software program that parses the text of a Lisp program and creates an in-memory List-based recursive data structure. Once the Lisp program is represented as a data structure, interpreting the program involves recursively evaluating these lists. This is the core of what a Lisp interpreter does, there is nothing more to it. Simple and Beautiful.
The following chapters in this book will walk you through the code that implements this interpreter. The interpreting process can be broken down into three phases.
- Lexing: Converting the Lisp program text into a stream of tokens.
- Parsing: Converting the stream of tokens into an in-memory recursive list data structure.
- Evaluation: Walking the in-memory recursive list and producing the final result.
In addition, the final chapter will implement a simple REPL to evaluate the Lisp program.
Lexer
Source
Code Walk Through
Lexer is a component of the interpreter that takes the program text and converts it to a stream of atomic units known as tokens. Every token has a type and may even have a value associated with it. In the case of our interpreter, there are four types of tokens. The four tokens can be represented using a Rust enum as follows.
pub enum Token {
Integer(i64),
Symbol(String),
LParen,
RParen,
}
- Integer: A signed 64-bit integer
- Symbol: Any group of characters other than an integer or parenthesis
- LParen: Left parenthesis
- RParen: Right parenthesis
The first step in implementing a lexer is to replace the parenthesis with an extra space before and after it. For example,
(define sqr (* x x))
will get converted to
( define sqr ( * x x ) )
With this simple trick, the process of tokenization involves splitting the Lisp program with whitespace.
let program2 = program.replace("(", " ( ")
.replace(")", " ) ");
let words = program2.split_whitespace();
Once the words for the program are obtained, they can be converted into tokens using Rust's pattern matching as follows
let mut tokens: Vec<Token> = Vec::new();
for word in words {
match word {
"(" => tokens.push(Token::LParen),
")" => tokens.push(Token::RParen),
_ => {
let i = word.parse::<i64>();
if i.is_ok() {
tokens.push(Token::Integer(
i.unwrap()));
} else {
tokens.push(Token::Symbol(
word.to_string()));
}
}
}
}
At this point, we have a vector of tokens for the entire Lisp program. Note that a vector in Rust is a stack, hence the tokens are stored in the vector in the reverse order as shown below with an example.
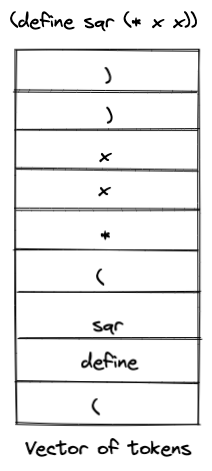
Testing
The lexer code can be unit tested as shown below
let tokens = tokenize("(+ 1 2)");
assert_eq!(
tokens,
vec![
Token::LParen,
Token::Symbol("+".to_string()),
Token::Integer(1),
Token::Integer(2),
Token::RParen,
]
);
To cement your understanding of the Lexing process please go through the remaining tests in lexer.rs
Parser
Source
Code Walk Through
The job of the parser is to take the vector of tokens and convert it into a recursive list structure (mentioned in the introduction). This recursive list structure is an in-memory representation of the Lisp program.
Object model
Before diving into the details of how the recursive list structure is created, we need to first define the objects that will make up the elements of the list. This is done in the object Rust module with an enum defined as follows
pub enum Object {
Void,
Integer(i64),
Bool(bool),
Symbol(String),
Lambda(Vec<String>, Vec<Object>),
List(Vec<Object>),
}
- Void: An empty object
- Integer: A signed 64-bit integer
- Bool: A boolean value
- Symbol: A Lisp symbol, similar to the Symbol token
- Lambda: Function object, with the first vector representing the parameter labels and the second vector representing the body of the function. This object is not used during parsing but will be used during the evaluation phase of the interpreter.
- List: List object
Parser
The parser for the Lisp dialect is a simple recursive function. It takes a vector of tokens (in reverse) generated by the lexer and generates a single List Object representing the entire Lisp program. The core logic of the parser is implemented by the recursive parse_list function as shown below. It expects a vector of tokens, with the first token of the vector being a left parenthesis indicating the start of the list. The function then proceeds to process the elements of the list one at a time. If it encounters atomic tokens such as an integer or symbol it creates corresponding atomic objects and adds them to the list. If it encounters another left parenthesis it recurses with the remaining tokens. Finally, the function returns with the list object when it encounters the right parenthesis.
let token = tokens.pop();
if token != Some(Token::LParen) {
return Err(ParseError {
err: format!("Expected LParen, found {:?}",
token),
});
}
let mut list: Vec<Object> = Vec::new();
while !tokens.is_empty() {
let token = tokens.pop();
if token == None {
return Err(ParseError {
err: format!("Insufficient tokens"),
});
}
let t = token.unwrap();
match t {
Token::Integer(n) =>
list.push(Object::Integer(n)),
Token::Symbol(s) =>
list.push(Object::Symbol(s)),
Token::LParen => {
tokens.push(Token::LParen);
let sub_list = parse_list(tokens)?;
list.push(sub_list);
}
Token::RParen => {
return Ok(Object::List(list));
}
}
}
Testing
The above parsing code can be unit tested as follows
let list = parse("(+ 1 2)").unwrap();
assert_eq!(
list,
Object::List(vec![
Object::Symbol("+".to_string()),
Object::Integer(1),
Object::Integer(2),
])
);
To cement your understanding of the parsing process please go through the remaining tests in parser.rs
Evaluator
Now comes the most exciting part of the project. Evaluation is the final step that will produce the result for the Lisp program. At a high level, the evaluator function recursively walks the List-based structure created by the parser and evaluates each atomic object and list (recursively), combines these intermediate values, and produces the final result.
Source
Code Walk Through
The evaluator is implemented using the recursive eval_obj function. The eval_obj function takes the List object representing the program and the global env variable (a simple hashmap) as the input. The function then starts processing the List object representing the program by iterating over each element of this list
fn eval_obj(obj: &Object, env: &mut Rc<RefCell<Env>>)
-> Result<Object, String>
{
match obj {
Object::Void => Ok(Object::Void),
Object::Lambda(_params, _body) => Ok(Object::Void),
Object::Bool(_) => Ok(obj.clone()),
Object::Integer(n) => Ok(Object::Integer(*n)),
Object::Symbol(s) => eval_symbol(s, env),
Object::List(list) => eval_list(list, env),
}
}
In the case of the atomic objects such as an integer and boolean, the evaluator simply returns a copy of the object. In the case of the Void and Lambda (function objects), it returns the Void object. We will now walk through the eval_symbol and eval_list functions which implement most of the functionality of the evaluator.
eval_symbol
Before understanding the eval_symbol function, it is important to understand the design of how variables are implemented for the Lisp interpreter.
The variables are just string labels assigned to values and they are created using the define keyword. Note a variable can be assigned atomic values such as integer or a boolean or it can be assigned function objects
(
(define x 1)
(define sqr (lambda (r) (* r r)))
)
The above Lisp code defines (or creates) two variables with the names x and sqr that represent an integer and function object respectively. Also, the scope of these variables lies within the list object that they are defined under. This is achieved by storing the mapping from the variable names (strings) to the objects in a map-like data structure called Env as shown below.
// env.rs
pub struct Env {
parent: Option<Rc<RefCell<Env>>>,
vars: HashMap<String, Object>,
}
The interpreter creates an instance of Env at the start of the program to store the global variable definitions. In addition, for every function call, the interpreter creates a new instance of env and uses the new instance to evaluate the function call. This new instance of env contains the function parameters as well as a back pointer to the parent env instance from where the function is called as shown below with an example
(
(define m 10)
(define n 12)
(define K 100)
(define func1 (lambda (x) (+ x K)))
(define func2 (lambda (x) (- x K)))
(func1 m)
(func2 n)
)
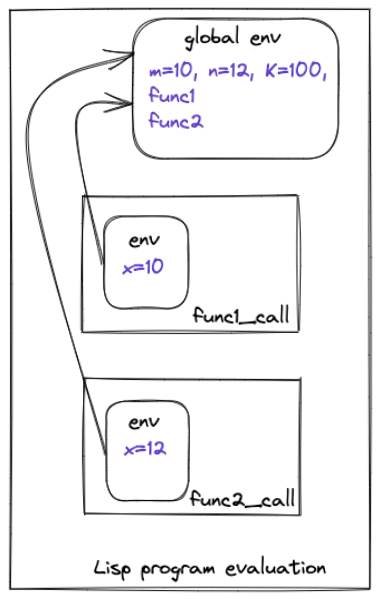
This concept will become clearer as we will walk through the code.
The job of eval_symbol is to look up the Object bound to the symbol. This is done by recursively looking up in the passed env variable or any of its parent env until the root env of the program.
let val = env.borrow_mut().get(s);
if val.is_none() {
return Err(format!("Unbound symbol: {}", s));
}
Ok(val.unwrap().clone())
eval_list
The eval_list function is the core of the evaluator and is implemented as shown below.
let head = &list[0];
match head {
Object::Symbol(s) => match s.as_str() {
"+" | "-" | "*" | "/" | "<" | ">" | "=" | "!=" => {
return eval_binary_op(&list, env);
}
"if" => eval_if(&list, env),
"define" => eval_define(&list, env),
"lambda" => eval_function_definition(&list),
_ => eval_function_call(&s, &list, env),
},
_ => {
let mut new_list = Vec::new();
for obj in list {
let result = eval_obj(obj, env)?;
match result {
Object::Void => {}
_ => new_list.push(result),
}
}
Ok(Object::List(new_list))
}
}
This function peeks at the head of the list and if the head does not match the symbol object, it iterates all of the elements of the list recursively evaluating each element and returning a new list with the evaluated object values.
Variable definitions
If the head of the list in the eval_list function matches the define keyword, for example
(define sqr (lambda (x) (* x x)))
the eval_define function calls eval_obj on the third argument of the list and assigns the evaluated object value to the symbol defined by the second argument in the list. The symbol and its object value are then stored in the current env.
let sym = match &list[1] {
Object::Symbol(s) => s.clone(),
_ => return Err(format!("Invalid define")),
};
let val = eval_obj(&list[2], env)?;
env.borrow_mut().set(&sym, val);
In the example above the symbol sqr and the function object representing the lambda will be stored in the current env. Once the function sqr has been defined in this manner, any latter code can access the corresponding function object by looking up the symbol sqr in env.
Binary operations
If the head of the list in the eval_list function matches a binary operator, the list is evaluated on the basis of the type of the binary operator, for example
(+ x y)
the eval_binary_op function calls the eval_obj on the second and third element of the list and performs the binary sum operation on the evaluated values.
If statement
If the head of the list in the eval_list function matches the if keyword, for example
(if (> x y) (x) (y))
the eval_if function calls eval_obj on the second element of the list and depending upon whether the evaluated value is true or false, calls the eval_obj on either the third or fourth element of the list and returns the value
let cond_obj = eval_obj(&list[1], env)?;
let cond = match cond_obj {
Object::Bool(b) => b,
_ => return Err(format!("Condition must be a boolean")),
};
if cond == true {
return eval_obj(&list[2], env);
} else {
return eval_obj(&list[3], env);
}
Lambda
As mentioned earlier, the lambda (or function) object consists of two vectors
Lambda(Vec<String>, Vec<Object>)
If the head of the list in the eval_list function matches the lambda keyword, for example
(lambda (x) (* x x))
the eval_function_definition function evaluates the second element of the list as a vector of parameter names.
let params = match &list[1] {
Object::List(list) => {
let mut params = Vec::new();
for param in list {
match param {
Object::Symbol(s) => params.push(s.clone()),
_ => return Err(format!("Invalid lambda parameter")),
}
}
params
}
_ => return Err(format!("Invalid lambda")),
};
The third element of the list is simply cloned as the function body.
let body = match &list[2] {
Object::List(list) => list.clone(),
_ => return Err(format!("Invalid lambda")),
};
Ok(Object::Lambda(params, body))
The evaluated parameter and body vector are returned as the lambda object
Function Call
If the head of the list is a Symbol object and it does not match any of the aforementioned keywords or binary operators, the interpreter assumes that the Symbol object maps to a Lambda (function object). An example of the function call in Lisp is as follows
(find_max a b c)
To evaluate this list the eval_function_call function is called. This function first performs the lookup for the function object using the function name, find_max in the case of this example.
let lamdba = env.borrow_mut().get(s);
if lamdba.is_none() {
return Err(format!("Unbound symbol: {}", s));
}
If the function object is found, a new env object is created. This new env object has a pointer to the parent env object. This is required to get the values of the variables not defined in the scope of the function.
let mut new_env = Rc::new(
RefCell::new(
Env::extend(env.clone())));
The next step in evaluating the function call requires preparing the function parameters. This is done by iterating over the remainder of the list and evaluating each parameter. The parameter name and the evaluated object are then set in the new env object.
for (i, param) in params.iter().enumerate() {
let val = eval_obj(&list[i + 1], env)?;
new_env.borrow_mut().set(param, val);
}
Finally, the function body is evaluated by passing the new_env, which contains the parameters to the function
let new_body = body.clone();
return eval_obj(&Object::List(new_body), &mut new_env);
REPL
Source
Code Walk Through
The REPL is the simplest part of the interpreter implementation. It uses the linefeed crate to implement the functionality.
The REPL first creates an instance of env to hold the global variables for the interpreter.
let mut env = Rc::new(RefCell::new(env::Env::new()));
The REPL is a simple while loop that takes one line as an input from the user, evaluates it, and prints out the evaluated object. The REPL is terminated if the user enters the exit keyword.
while let ReadResult::Input(input) =
reader.read_line().unwrap() {
if input.eq("exit") {
break;
}
let val = eval::eval(input.as_ref(), &mut env)?;
match val {
Object::Void => {}
Object::Integer(n) => println!("{}", n),
Object::Bool(b) => println!("{}", b),
Object::Symbol(s) => println!("{}", s),
Object::Lambda(params, body) => {
println!("Lambda(");
for param in params {
println!("{} ", param);
}
println!(")");
for expr in body {
println!(" {}", expr);
}
}
_ => println!("{}", val),
}
}
What's next
Congratulations!!! if you have made it so far, you now have a grasp of how to implement a Lisp interpreter in Rust. A few easy things to try next would be to add support for float point numbers, unsigned integers, and strings. Once you are able to successfully make these changes the next thing to try would be to add support for the List datatype followed by support for the functional constructs of map, filter, and reduce.
With this knowledge, you should be then able to implement an interpreter for any non-trivial language.